Pipelining is a technique used to improve the execution throughput of a CPU by using the processor resources in a more efficient manner.
The basic idea is to split the processor instructions into a series of small independent stages. Each stage is designed to perform a certain part of the instruction. At a very basic level, these stages can be broken down into:
- Fetch Unit Fetch an instruction from memory
- Decode Unit Decode the instruction be executed
- Execute Unit Execute the instruction
- Write Unit Write the result back to register or memory
There will be a dedicated CPU module for each of the stages mentioned above.
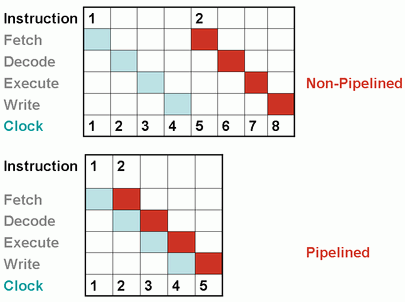
On a non-pipelined CPU, when a instruction is being processed at a particular stage, the other stages are at an idle state – which is very inefficient. If you look at the diagram, when the 1st instruction is being decoded, the Fetch, Execute and Write Units of the CPU are not being used and it takes 8 clock cycles to execute the 2 instructions.
On the other hand, on a pipelined CPU, all the stages work in parallel. When the 1st instruction is being decoded by the Decoder Unit, the 2nd instruction is being fetched by the Fetch Unit. It only takes 5 clock cycles to execute 2 instructions on a pipelined CPU.
Note that increasing the number of stages in the pipeline will not always result in an increase of the execution throughput. On a non-pipelined CPU, an instruction could only take 3 cycles, but on a pipelined CPU it could take 4 cycles because of the different stages involved. Therefore, a single instruction might require more clock cycles to execute on a pipelined CPU. But the time taken to complete the execution of multiple instructions gets faster in pipelined CPUs. So there needs to a balance in between.
One of the major complications with deep pipelining (eg, 31-stage pipelining used in some of the Intel Pentium 4 processors) is when a conditional branch instruction is being executed – due to the fact that the processor will not be able to determine the location of the next instruction, therefore it has to wait for the branch instruction to finish and the whole pipeline may need to be flushed as a result. If a program has many conditional branch instructions, pipelining could have a negative effect on the overall perfomance. To alleviate this problem, branch prediction can be used, but this too can have a negative effect if the branches are predicted wrongly.
Due to the different ways AMD and Intel implement pipelining in their CPUs, comparing their CPUs purely based on the clock speed is never accurate.
Mohamed Ibrahim
ibrahim = { interested_in(unix, linux, android, open_source, reverse_engineering); coding(c, shell, php, python, java, javascript, nodejs, react); plays_on(xbox, ps4); linux_desktop_user(true); }
